defaultReadObject分析
起因是想重新了解下反序列化,在看HashMap的readObject时,看到了defaultReadObject(),想到在重写readOject()中基本都遇到过,于是想了解下这个函数的具体作用以及实现原理。
readObject
先看下执行原生readOject()都发生了什么
测试代码:
1 | public class SerializeTest { |
Animals
1 | public class Animals implements Serializable { |
流程分析
在执行readOject()后会执行readOject0,上半部分主要是快数据模式的判断,详细点说就是:在序列化和反序列化时,会采用块模式进行存储提高效率
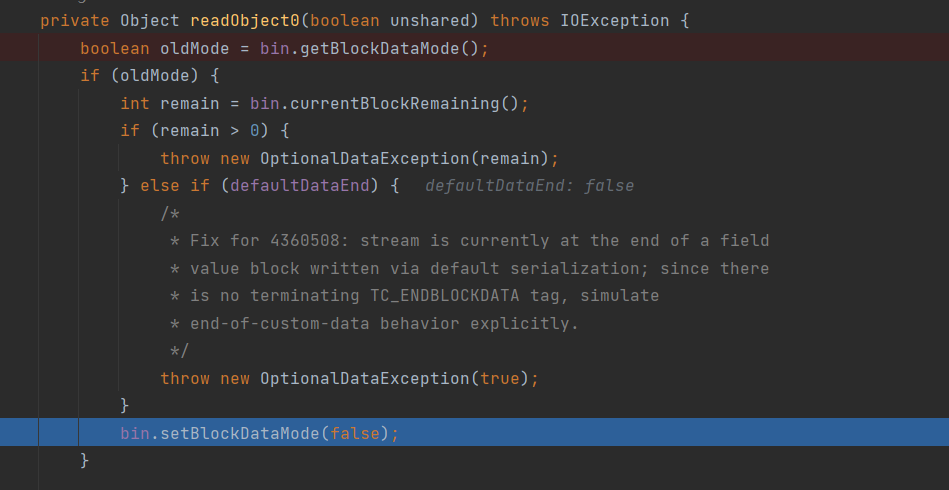
而这里就是判断是否为该模式,是的话则检查当前块中是否还有剩余的数据,如果有的话则说明(有剩余未处理的数据),会抛出异常;如若没问题,最后就是将该模式设为false关闭掉。
这个块数据模式的设置就在ObjectInputStream,其中bin的值就是该模式下的序列化数据
1 | public ObjectInputStream(InputStream in) throws IOException { |
之后tc = bin.peekByte()) == TC_RESET 进行读取一个字节的数据来进行判断,经过一级级调用最后到了read()此时pos为4,
peekByte方法,不是读取当前的字节,而是后一个字节。但是readByte方法则是读取当前所在的字节,不是后一个。这两个方法还是不一样的!
所以取出的数据即:115赋值给tc(前边的-84,-19,0,5是序列化数据开头的标识信息)
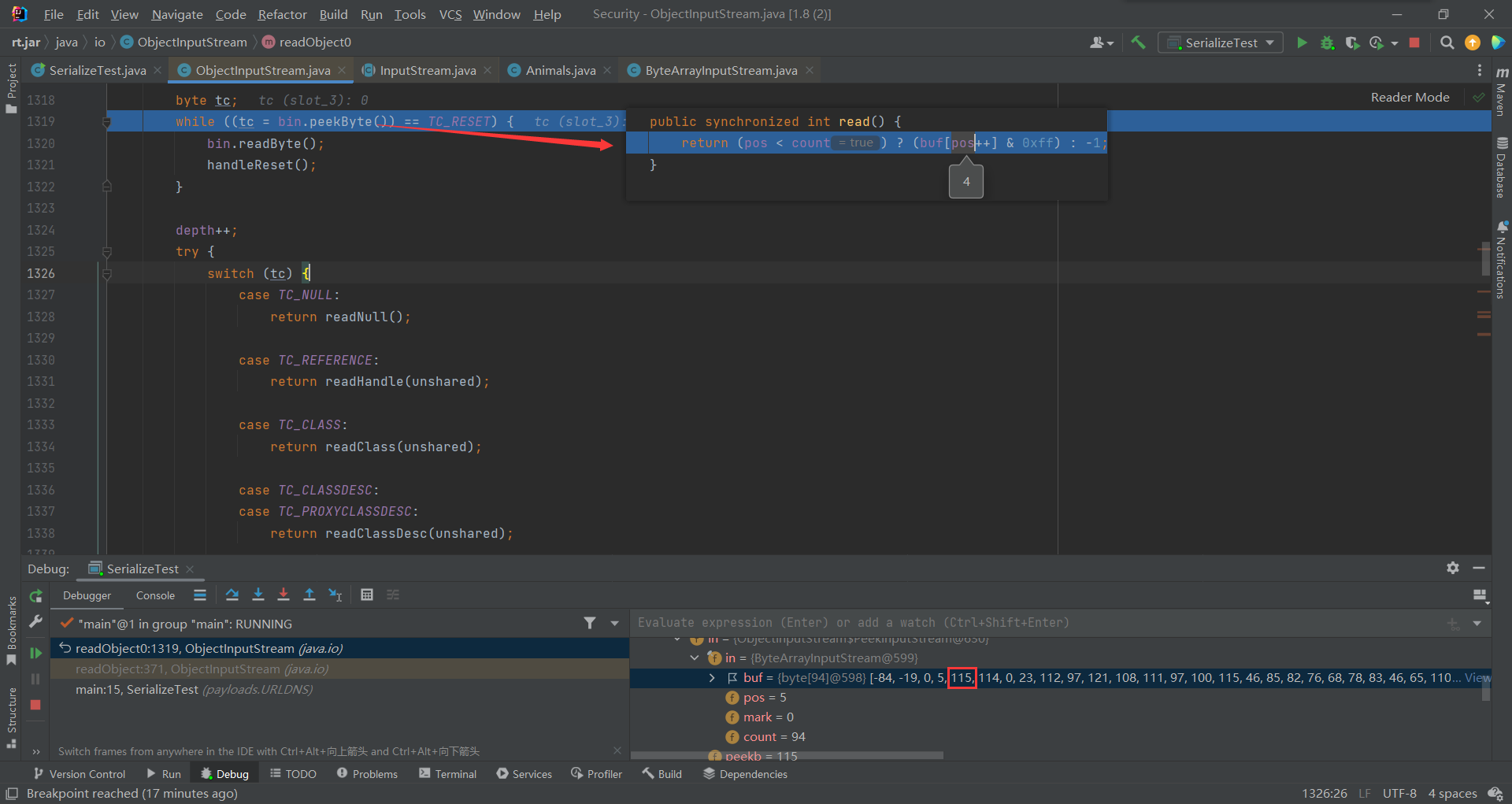
switch语句找到对应115的case语句,处理对象数据,跟进下readOrdinaryObject
1 | case TC_OBJECT: |
首先判断读取一个字节数据进行判断(刚有提到readByte是读取当前字节,所以及时pos刚才自增了单读出来的还是115),接着到了readClassDesc()读取类描述符。
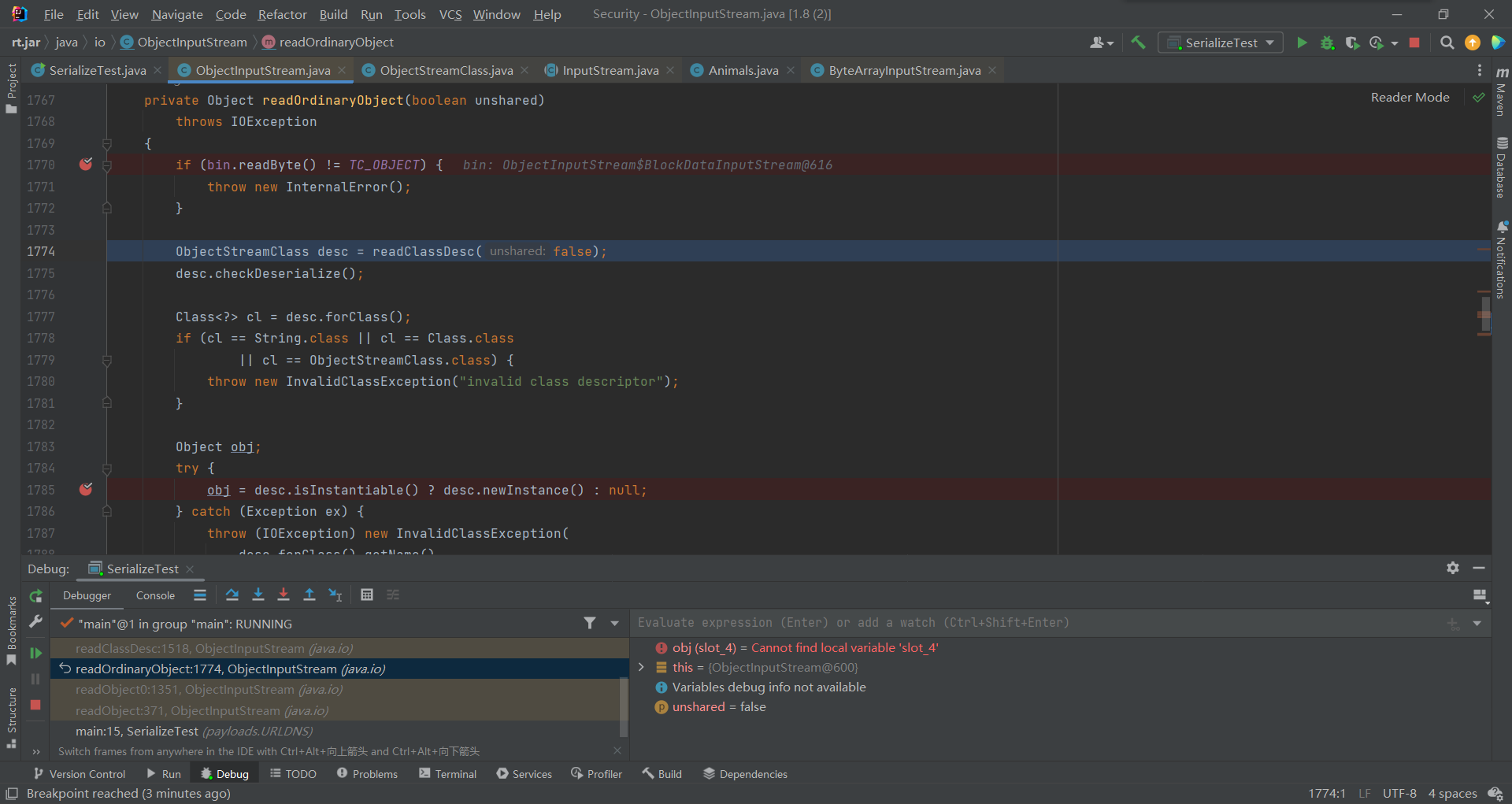
这次调用的是peekByte(),所以读取下一个字节114,进入TO_CLASSDESC处理类对象 (现在等于是在TC_OBJECT 对象数据中处理TO_CLASSDESC类数据)
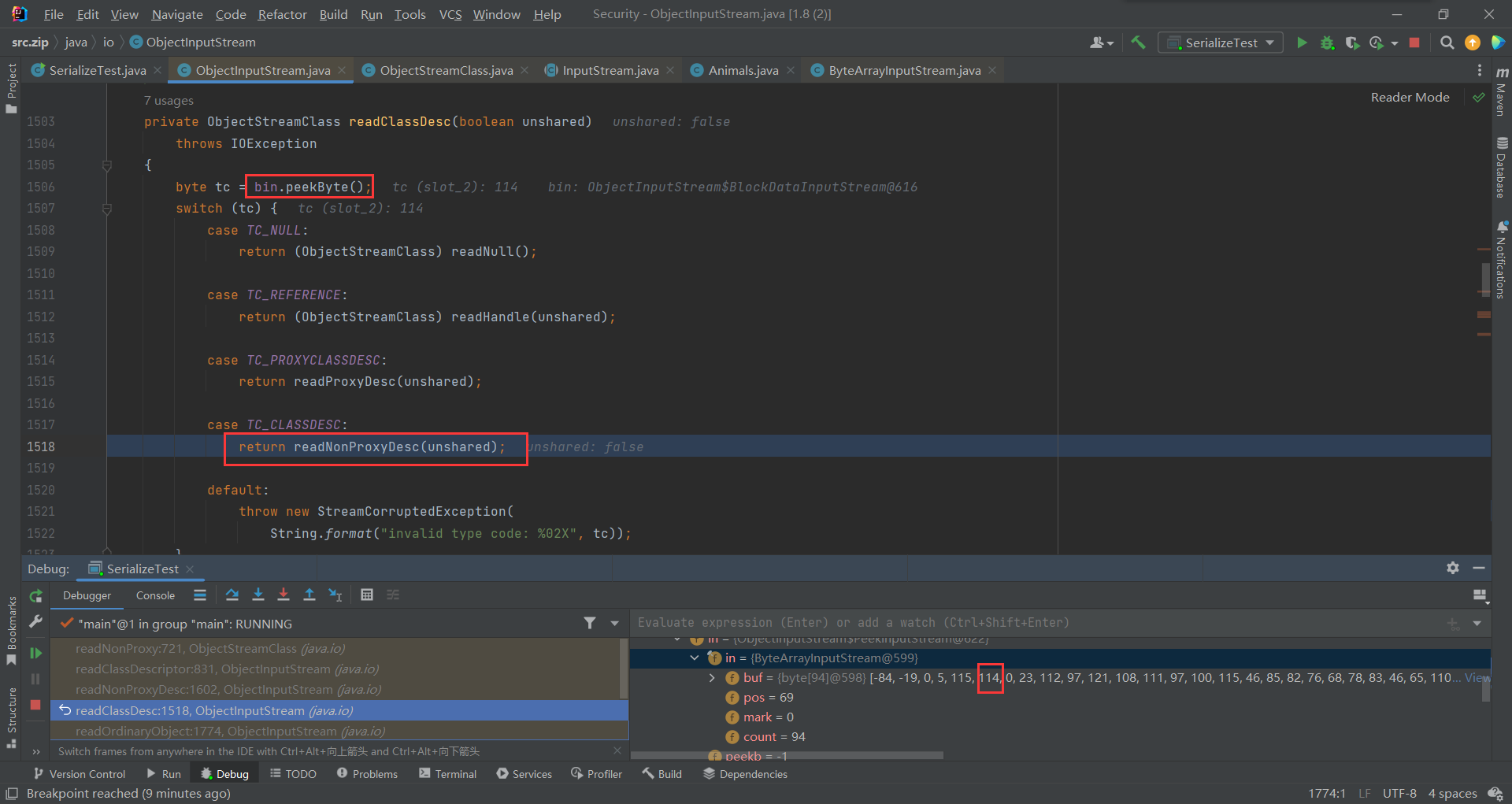
进入readNonProxyDesc(),主要分为两部readClassDescriptor()和resolveClass()
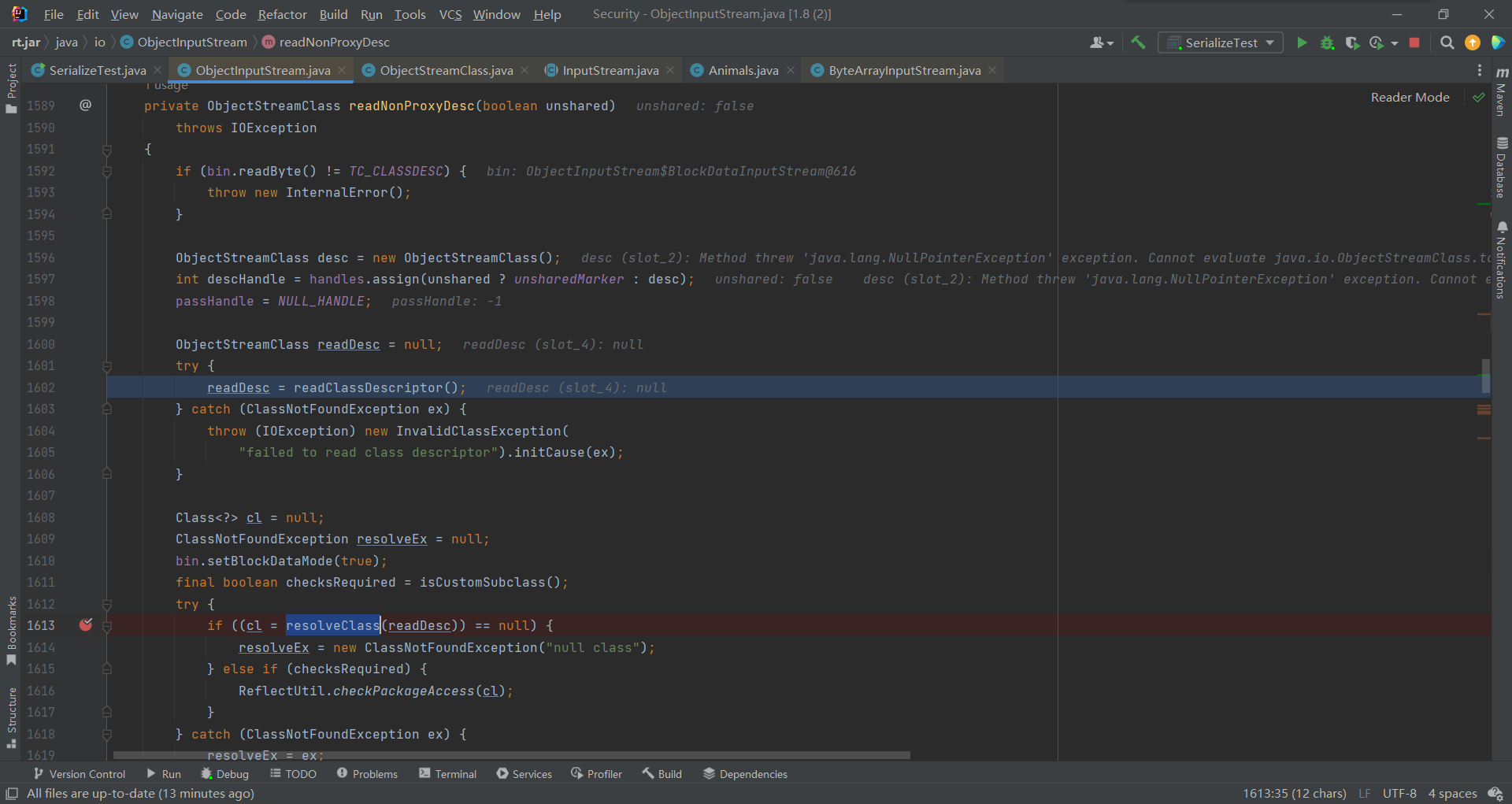
先看readClassDescriptor(),里边又执行了readNonProxy(),主要是拿到类中的两个字段——>cat、dog
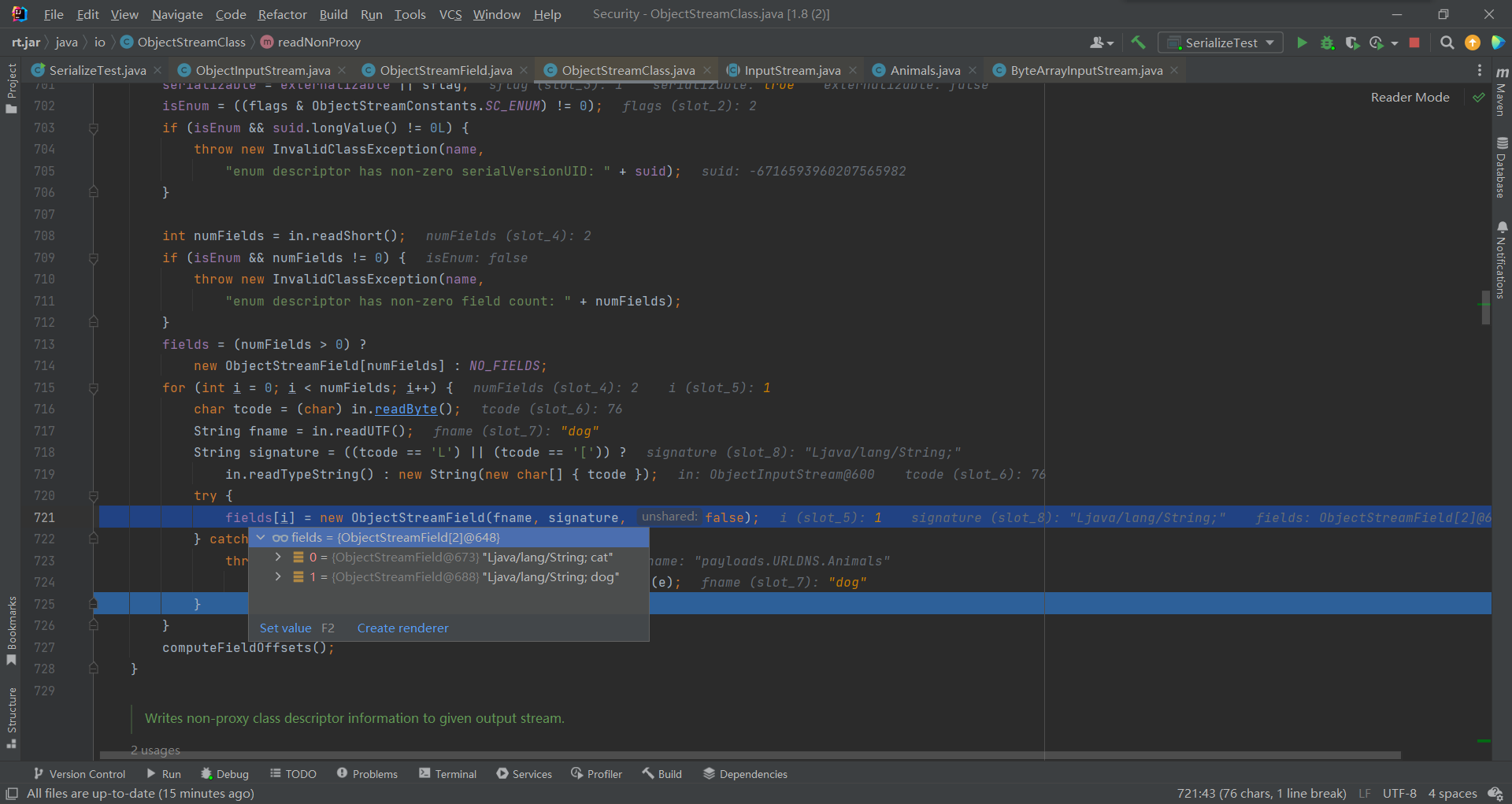
取出后回到readNonProxyDesc(),将readClassDescriptor()获取到的类及其字段返回给readDesc属性,通过resolveClass()默认类加载器加载了readDesc指定名称的类即Animals,并触发类的初始化
1 | protected Class<?> resolveClass(ObjectStreamClass desc) |
接着回到readOrdinaryObject(),将刚才加载的类赋值给desc,并判断其是否可以进行反序列化,接着通过forClass拿到目标class对象
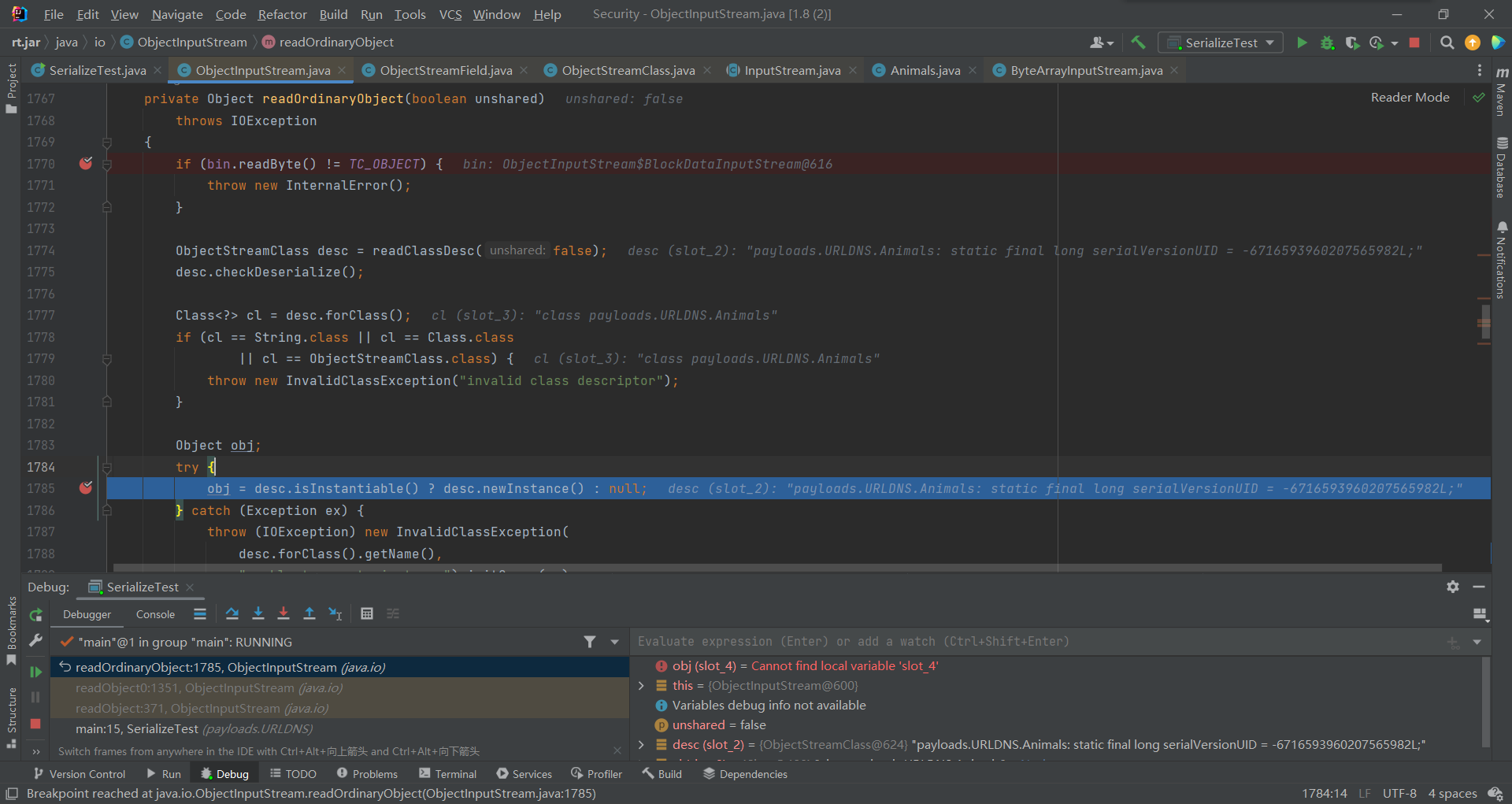
下边执行isInstantiable()判断其是否可以进行实例化,之后实例化了desc,这时obj就成为了真正的Animals对象。(这里有个单例问题后边再说)
Animals实例创建好之后,还需要对其中的每个字段进行填充,相关操作体现在readSerialData方法中
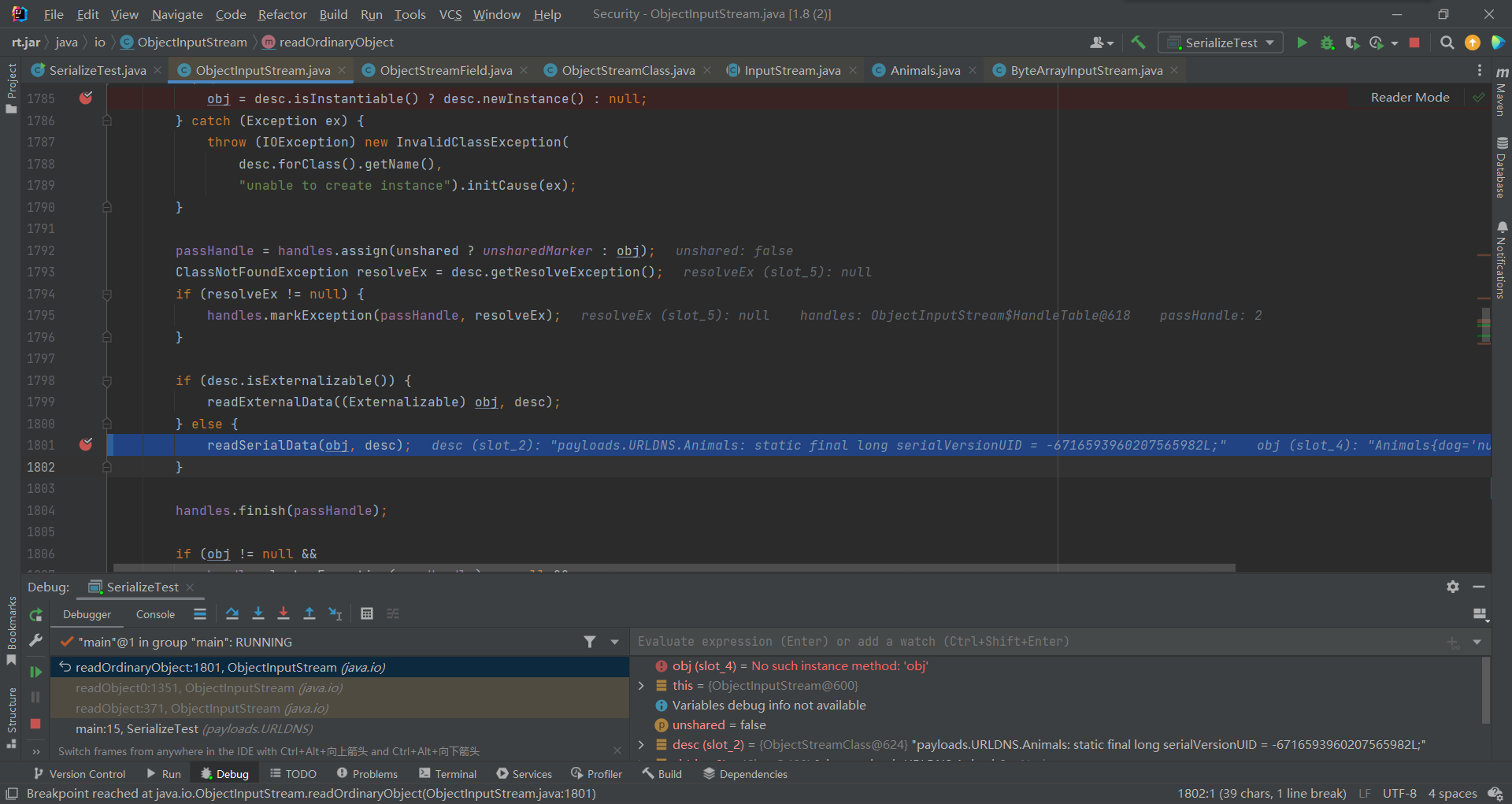
readSerialData方法有两种情况:
这个方法首先会对通过hasReadObjectMethod()对传入的对应描述符对象进行判断,看其是否存在readObjectMethod属性,存在就通过反射调用
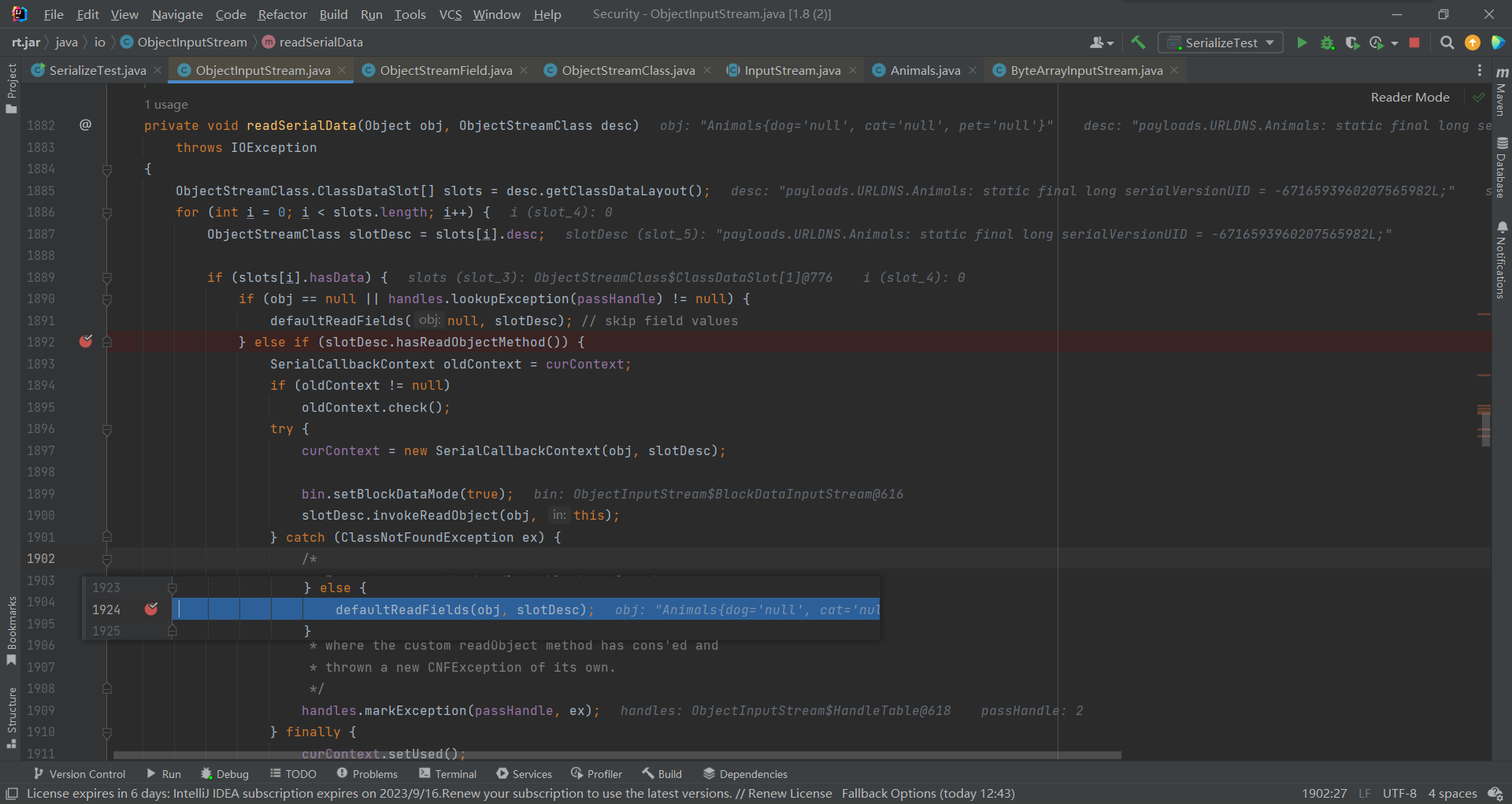
而我们在Animals类中并没有重写readOject(),所以走到了下边else中的defaultReadFields()
其中通过反序列化读取到各字段的值,并反射对其进行填充,此刻obj对象实例,已经有了对应的字段和值
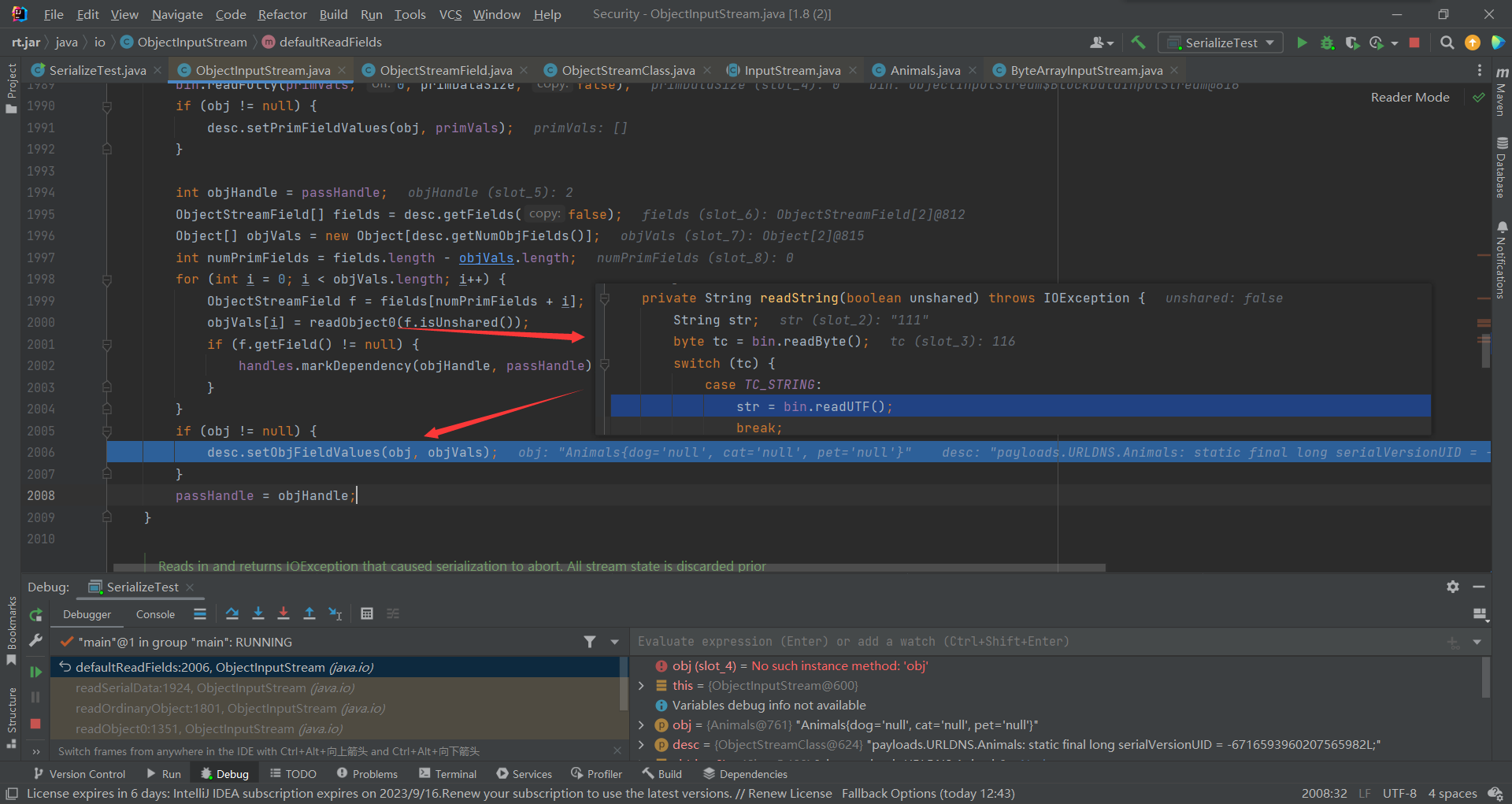
单例问题
走出readSerialData()后,就到了下边的hasReadResolveMethod(),判断是否有ReadResolve方法
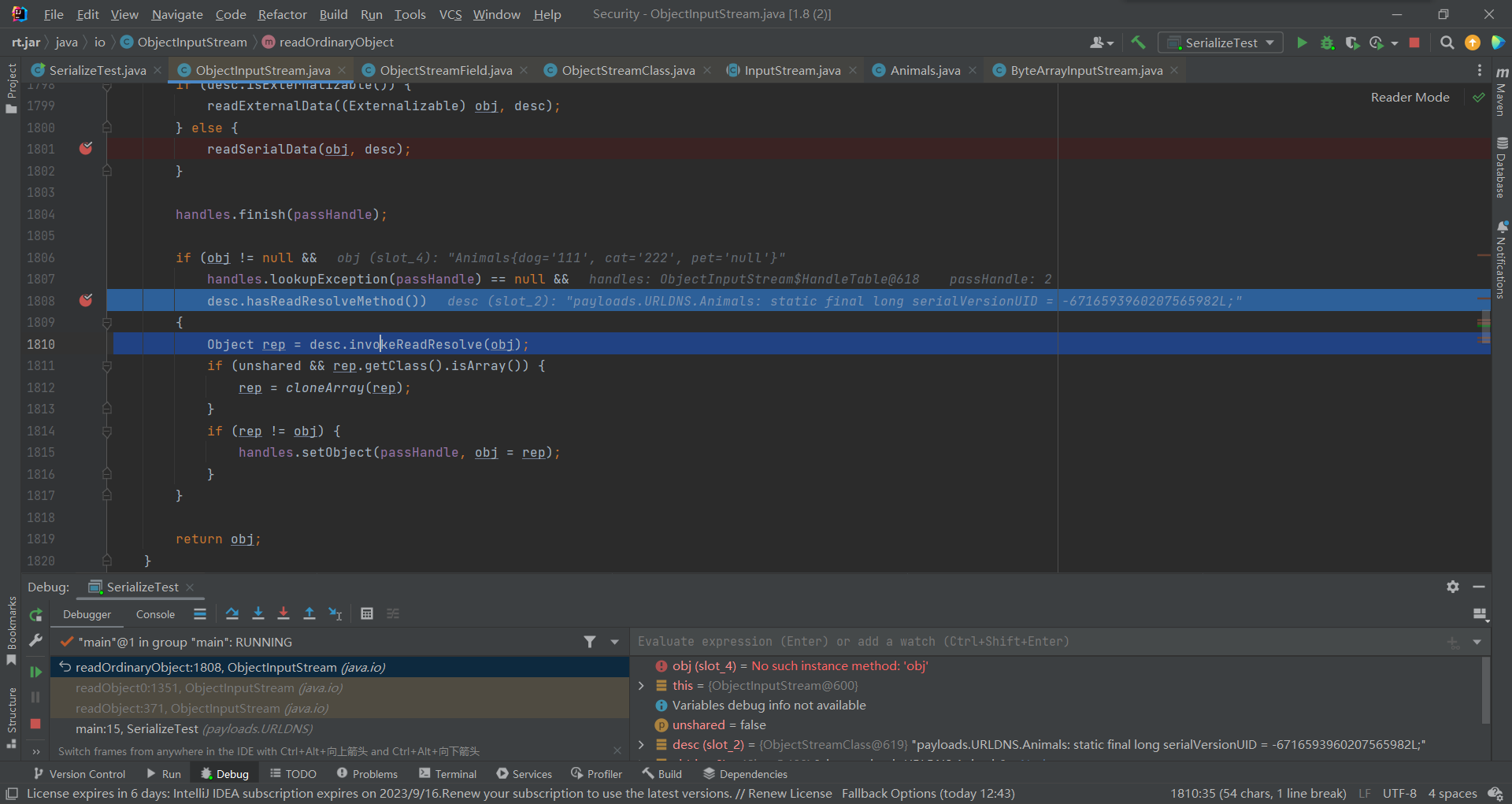
而这个方法其实就是为了解决单例问题的,在前边有这么一段代码,当调用newInstance()进行实例化后,此时JVM会为其创建一个新的实例对象,这种做法会破坏单例模式。
1 | try { |
所以可以用readResolve()解决这个问题
1 | private Object readResolve() { |
当然这个对当前反序列化没有影响,所以了解下即可,可参考:单例、序列化和readResolve()方法 - 知乎 (zhihu.com)
重写readObejct
在上边提到readSerialData()有两种情况,分别是调用readObject()和defaultReadFields()填充字段,所以这里看下重写readOject()后会怎样
在Animals类中加上:
1 | private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException { |
前边都是一样的所以就不看了,直接到readSerialData()里,由于这次已经有了readOject()方法,所以在hasReadObjectMethod()判断结束后,进入了if语句,反射调用了重写的readObject()
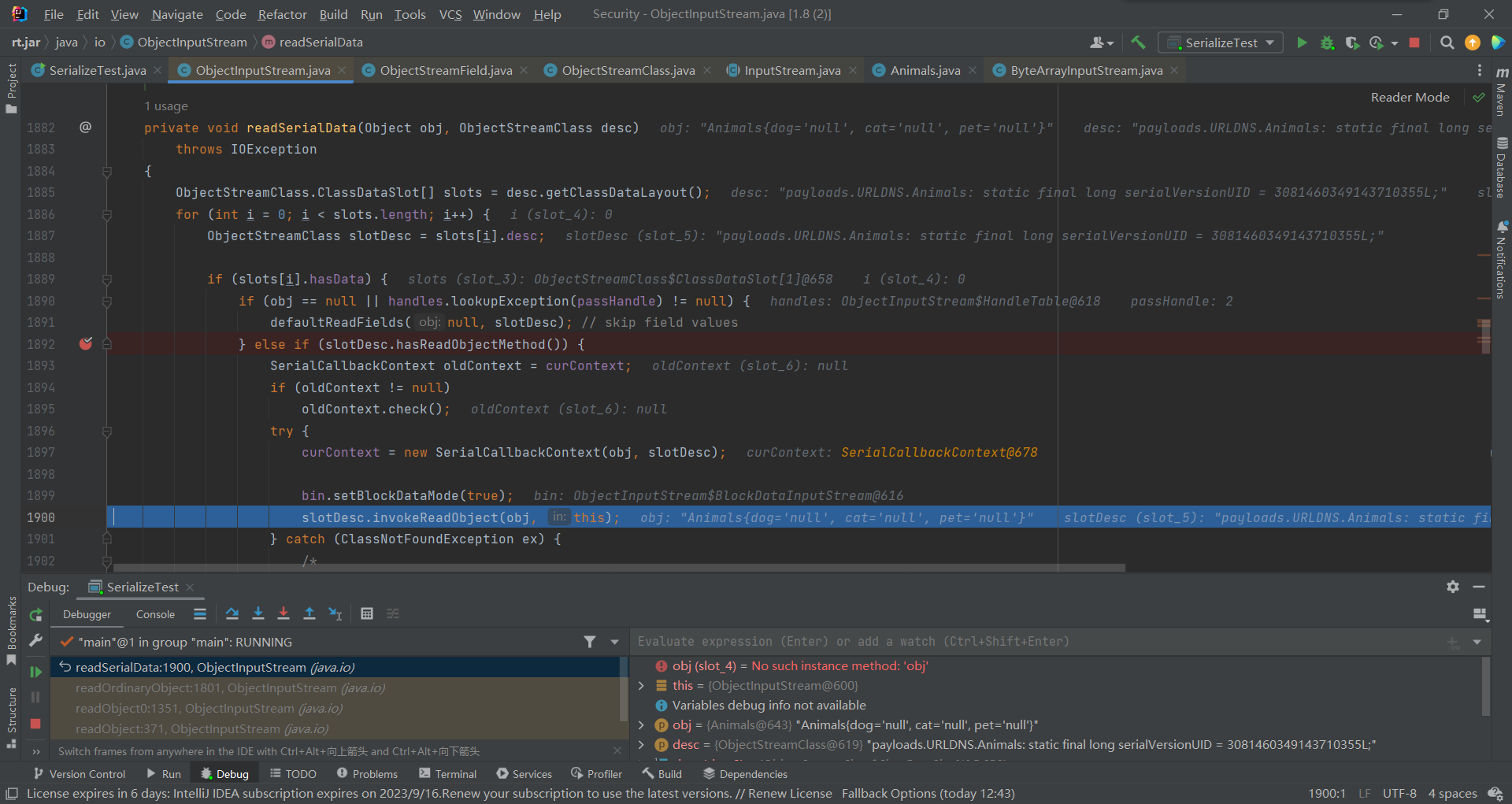
由于我们没有在readObejct()中,并没有写readUTF()或其他实例化语句,所以这里并没有对属性进行填充,就导致了:

这时就引出了defaultReadObject()
defaultReadObject
defaultReadObject其实在重写的readOject方法中很多都有见过
根据注解,作用主要是:从该流中读取当前类的非静态和非瞬态字段。这只能从正在反序列化的类的readObject方法调用。
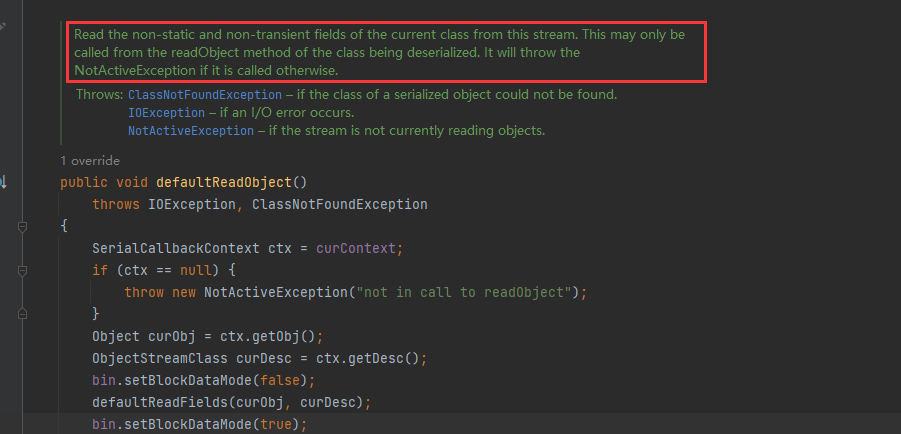
其实就是对各个字段值进行初始化,defaultReadObject() 主要执行以下操作:
- 根据默认的规则从输入流中读取字节流,将其转换为对象的字段值。
- 将读取到的字段值分配给相应的字段。
流程分析
将readObject()改成
1 | private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException { |
还是到之前反射调用readOject()的部分,这时执行了defaultReadObject()
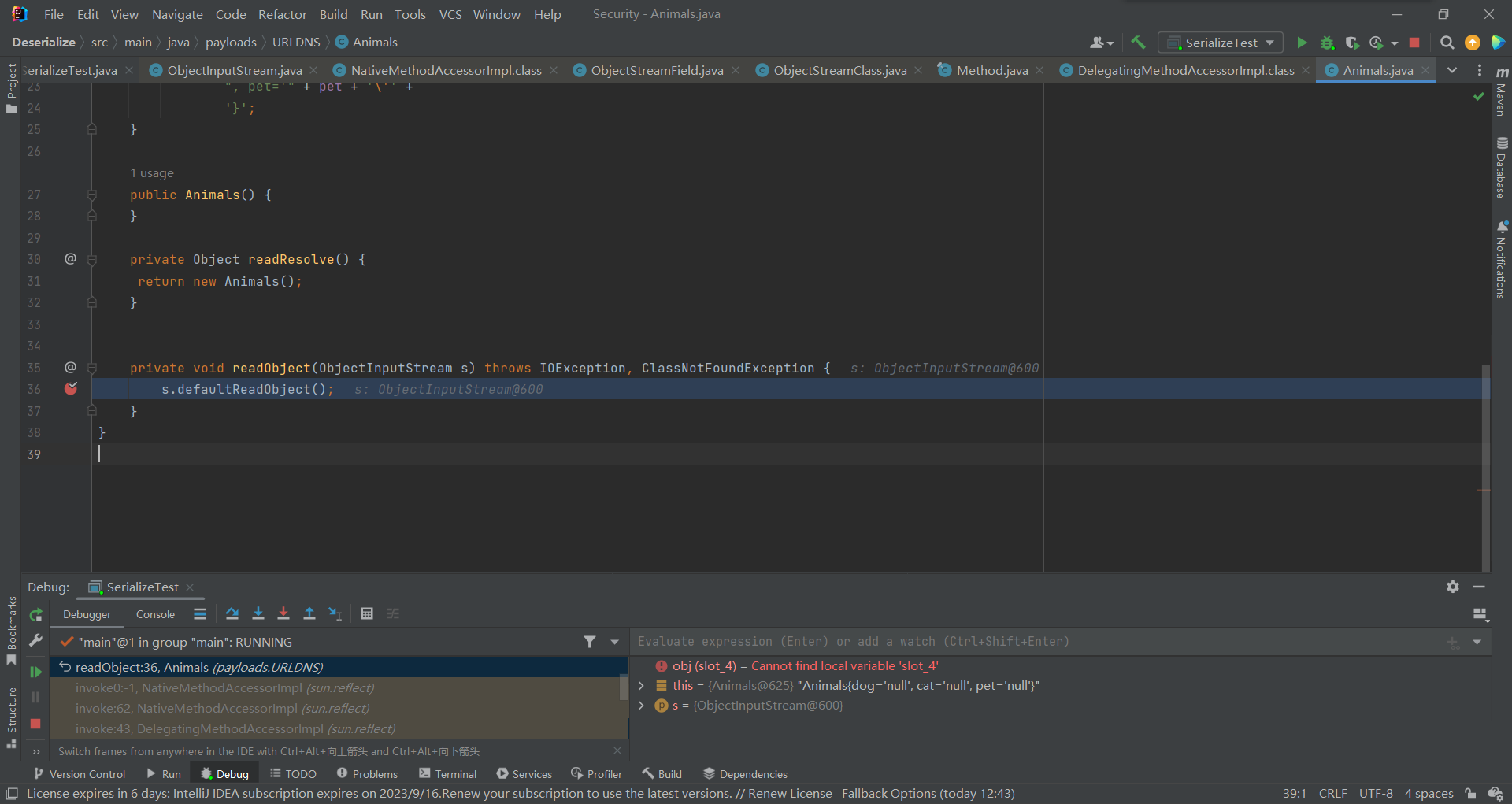
之后执行到了defaultReadFields(),在上边字段填充中提到过,剩下过程就跟之前一样了
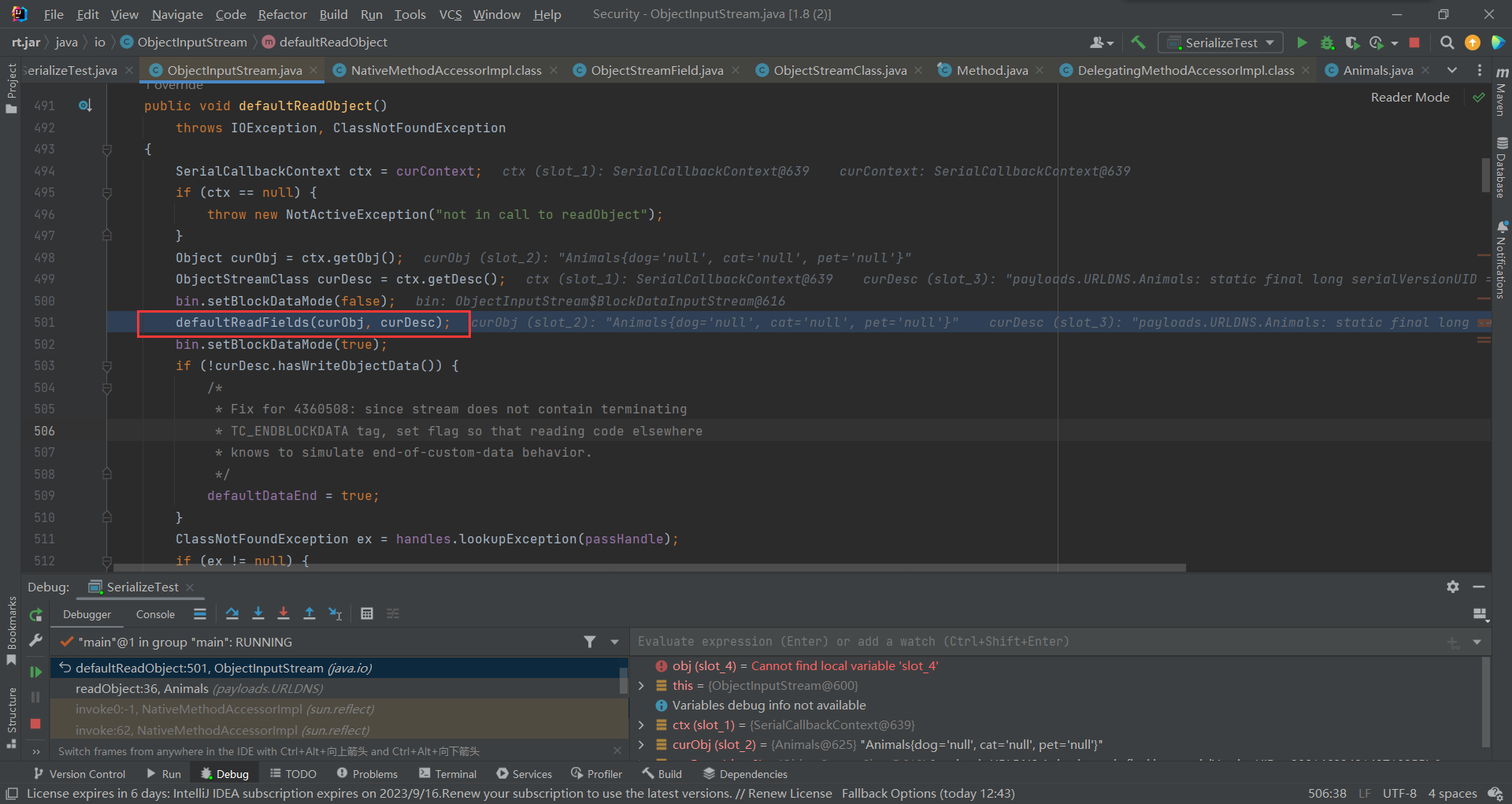
此时执行后的结果:

Others
在CTF中,有通过对Resolve()重写,进行二次反序列化的利用,如:javaDeserializeLabs — labs5、AliyunCTF — ezbean
除此外还见过一次通过resolveClass设置拦截点的题,做个简单记录
1 | public class MyownObjectInputStream extends ObjectInputStream{ |